Abres la factura de tu proveedor de API al final del mes, ves el monto y piensas: «¿en serio gasté eso?».
Si estás construyendo agentes autónomos, pipelines de datos o automatizaciones con modelos de lenguaje, los tokens de salida son el gasto silencioso que te revienta el presupuesto. Y la brecha de precios entre proveedores es brutal: el mismo tipo de tarea puede costarte $30 por millón de tokens con GPT-5.5 o $0.87 con DeepSeek V4 Pro. La diferencia no es un porcentaje menor — es un factor de 34x.
Pero más barato no siempre es mejor. Y más caro no siempre es más preciso.
Este artículo desglosa los precios reales de las API más relevantes a mayo de 2026, los contrasta con benchmarks de precisión independientes, y te da tres estrategias concretas para recortar la factura sin sacrificar calidad donde importa.
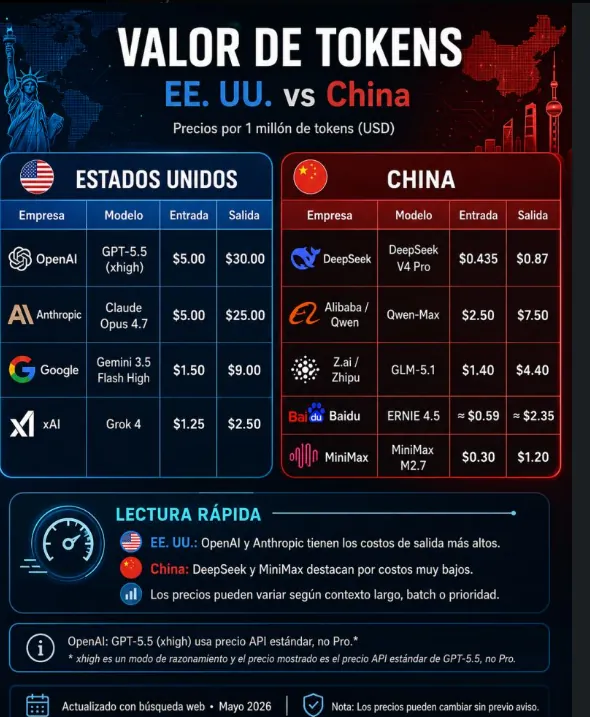
La tabla: EE. UU. vs China, precio por millón de tokens
Empecemos por los números crudos. Todos los precios están en USD por 1 millón de tokens, nivel API estándar (no enterprise ni compromisos de volumen).
Proveedores de EE. UU.
| Empresa | Modelo | Entrada | Salida |
|---|---|---|---|
| OpenAI | GPT-5.5 (xhigh) | $5.00 | $30.00 |
| Anthropic | Claude Opus 4.7 | $5.00 | $25.00 |
| Gemini 3.5 Flash High | $1.50 | $9.00 | |
| xAI | Grok 4 | $1.25 | $2.50 |
Proveedores de China
| Empresa | Modelo | Entrada | Salida |
|---|---|---|---|
| DeepSeek | DeepSeek V4 Pro | $0.435 | $0.87 |
| Alibaba / Qwen | Qwen-Max | $2.50 | $7.50 |
| Z.ai / Zhipu | GLM-5.1 | $1.40 | $4.40 |
| Baidu | ERNIE 4.5 | ~$0.59 | ~$2.35 |
| MiniMax | MiniMax M2.7 | $0.30 | $1.20 |
Lectura rápida:
- OpenAI y Anthropic tienen los costos de salida más altos.
- DeepSeek y MiniMax destacan por costos muy bajos.
- Los precios pueden variar según contexto largo, batch o prioridad.
Una nota sobre GPT-5.5: el precio de $5.00/$30.00 es el de la API estándar (xhigh). Existe un nivel «GPT-5.5 Pro» que escala a $30.00 (entrada) y $180.00 (salida) para tareas que requieren el máximo nivel de inferencia. Y sobre DeepSeek V4 Pro: los $0.435/$0.87 son a través de su proveedor oficial o nodos optimizados (como GMICloud). Si usas proveedores externos como Fireworks o DeepInfra, el costo sube a $1.74/$3.48 por millón.
Pero, ¿cuánto de preciso es cada uno?
El precio sin contexto de rendimiento no sirve. Aquí es donde la mayoría de las comparativas fallan: te muestran la tabla y te dejan decidir solo con el bolsillo. Veamos qué dicen los benchmarks independientes.
Modelos frontera: máxima precisión, alto costo
GPT-5.5 (OpenAI) — $5.00 / $30.00
El modelo más fuerte en lógica deductiva estática y retención de contexto gigante. Domina MMLU (92.4%) y Terminal-Bench (82.7%). Pero tiene un punto débil que muchos ignoran: en codificación agéntica autónoma, los reportes independientes de LiveBench le dan un score de 56.67. Es inconsistente cuando se lo deja ejecutar múltiples pasos sin supervisión humana.
Cuándo usarlo: ingresar un manual técnico de 500 páginas o jurisprudencia legal compleja y pedirle que correlacione cláusulas específicas. Sobresale analizando y «explicando» la estructura, pero no actuando solo.
Claude Opus 4.7 (Anthropic) — $5.00 / $25.00
Actualmente considerado el modelo líder para desarrolladores. Supera a GPT-5.5 en entornos de ingeniería de software real: SWE-bench Pro marca 64.3% vs 58.6% de GPT-5.5. Su precisión en visión artificial (Computer Use) dio un salto al 98.5%.
Cuándo usarlo: auditorías de ciberseguridad, resolución de tickets complejos de GitHub de principio a fin, o subir mockups de diseño densos para que genere la estructura base del código. Es el mejor modelo actual para flujos de trabajo autónomos sin intervención constante.
Modelos de alta eficiencia: alto volumen, precisión específica
Gemini 3.5 Flash High (Google) — $1.50 / $9.00
Alcanza 77% de precisión en análisis de datos y 80% en redacción de informes estructurados. Lo interesante es cómo lo logra: este modelo realiza un 40% más de llamadas a herramientas (tool calls) para buscar y verificar información antes de responder.
Cuándo usarlo: entornos donde la alucinación es inaceptable. Procesar registros clínicos, facturas, formularios regulatorios o hacer cruces de bases de datos internas (RAG) verificando los datos paso a paso.
DeepSeek V4 Pro — $0.435 / $0.87
Con 49 billones de parámetros activos (arquitectura MoE), rinde dentro del Top 10% global en generación de código estándar (58.5% win rate en Arena). Su tasa de error de validación de formato — JSON, esquemas estrictos — es de aproximadamente el 1%, compitiendo cara a cara con modelos 10 veces más caros en tareas acotadas.
Cuándo usarlo: pipelines de limpieza de datos masivos (ETL), traducciones a gran escala, generación de miles de pruebas unitarias, o clasificación de sentimientos para millones de reseñas.
Tres estrategias para recortar la factura (hasta un 60%)
Ahora lo práctico. Si estás desarrollando flujos con agentes autónomos o scripts en Python que procesan grandes volúmenes de datos, el costo de los tokens de salida y el reenvío del mismo contexto pueden multiplicar la factura rápidamente. Estas tres técnicas están integradas en las mismas API.
1. Prompt Caching (caché de contexto)
Los modelos más avanzados aplican descuentos masivos cuando se reenvía el mismo contexto. Ideal para esquemas de datos extensos o instrucciones base complejas que no cambian entre llamadas.
| Modelo | Precio entrada normal | Precio entrada cacheada | Descuento |
|---|---|---|---|
| Claude Opus 4.7 | $5.00 | $0.50 | 90% |
| GPT-5.5 | $5.00 | $0.50 | 90% |
| Gemini 3.5 Flash | $1.50 | $0.15 | 90% |
Si tu pipeline reenvía el mismo system prompt + esquema de datos en cada llamada (y lo hace — todos lo hacen), el prompt caching convierte el costo de entrada en centavos. Es la optimización con mayor impacto inmediato.
2. Procesamiento por lotes (Batch API)
Para tareas de procesamiento masivo — limpieza de datos, generación de reportes, clasificación — donde la respuesta en tiempo real no es obligatoria, las llamadas asíncronas por lotes reducen las tarifas a la mitad.
En Claude Opus 4.7 y GPT-5.5, el procesamiento Batch recorta el costo en un 50%. Opus 4.7 baja a $2.50 en entrada y $12.50 en salida. Combines eso con prompt caching y los tokens de entrada quedan en $0.25 por millón.
3. Enrutamiento de modelos (Model Routing)
La práctica recomendada en 2026. No tienes que casarte con un solo modelo.
La idea es sencilla: implementas un clasificador inicial muy económico (DeepSeek V4 Flash a $0.14 por millón de tokens). Si la petición del usuario es sencilla — resumir un texto, responder FAQs, formatear un JSON — el flujo se enruta al modelo barato. Si el prompt se detecta como matemática compleja, resolución de código o análisis financiero profundo, la API escala automáticamente a Claude Opus 4.7 o GPT-5.5.
Plataformas como Requesty.ai u OpenRouter ya implementan esto como servicio. Pero también puedes armar tu propio enrutador con un par de funciones en Python.
En lugar de usar el modelo más costoso para todo el flujo, distribuyes así:
- Claude Sonnet 4.6 ($3.00 / $15.00) o DeepSeek V4 Flash ($0.14 / $0.28) para limpieza, estructuración y formato.
- Opus 4.7 o GPT-5.5 exclusivamente para razonamiento financiero complejo o generación de resúmenes estratégicos.
Resultado: precisión donde importa, centavos donde no.
El chiste no es elegir uno — es saber cuándo usar cada uno
El error más común que veo en equipos de datos es elegir un modelo «favorito» y usarlo para todo. Es como usar un taladro industrial para colgar un cuadro.
La realidad de 2026 es que los modelos son herramientas especializadas con perfiles de costo-beneficio muy distintos:
- ¿Necesitas precisión absoluta en razonamiento complejo? GPT-5.5 o Opus 4.7. Paga los $25-30 de salida, pero solo para esas llamadas.
- ¿Procesamiento masivo con formato estricto? DeepSeek V4 Pro a $0.87 la salida. La calidad es suficiente y el ahorro es de 30x.
- ¿Entornos donde no puedes alucinar? Gemini 3.5 Flash High con su verificación automática.
- ¿Todo lo anterior en un mismo pipeline? Enrutamiento dinámico. Un clasificador de centavos decide quién responde cada pregunta.
Combina eso con prompt caching y batch API, y la factura que hoy te asusta se convierte en algo manejable — incluso escalando a millones de llamadas.
Fuentes consultadas: Anthropic Transparency Hub (abril 2026), Box AI Research Blog (mayo 2026), LMSYS Chatbot Arena y LiveBench Reports (mayo 2026), OpenRouter y Requesty.ai API Data.
Los precios pueden cambiar sin previo aviso. Última verificación: mayo 2026.
Deja una respuesta