TL;DR: La inteligencia de anuncios consiste en recolectar y analizar de forma sistemática la publicidad que tu competencia publica para descubrir qué mensajes, ofertas y creativos están usando. En este tutorial construyo un sistema completo: extraigo los anuncios públicos de la Biblioteca de anuncios de Meta con dos scripts de consola de Chrome (uno para los textos en CSV y otro para las imágenes), los proceso con un pipeline ETL en Python sobre SQLite, extraigo precios desde las imágenes con Claude Haiku 4.5 y lo visualizo todo en un dashboard de Streamlit. El caso real: el mercado de posgrados en Ecuador.
¿Qué es la inteligencia de anuncios y para qué sirve en marketing?
La inteligencia de anuncios es el proceso de recolectar, estructurar y analizar la publicidad activa de tus competidores para tomar decisiones de marketing basadas en evidencia, no en intuición. En lugar de adivinar qué funciona, observas directamente qué anuncios sigue pagando tu competencia y durante cuánto tiempo, lo que es una señal fuerte de rentabilidad.
En este proyecto la apliqué al mercado de posgrados en Ecuador: maestrías y diplomados que se promocionan en Facebook e Instagram. La app que construí responde preguntas concretas de marketing: ¿qué instituciones invierten más en pauta?, ¿qué temas (Recursos Humanos, Seguridad Ocupacional, Gestión Pública…) están saturados?, ¿qué precios anuncia cada competidor? y, sobre todo, ¿qué anuncios llevan más tiempo en circulación?
Esa última métrica es la joya: un anuncio que lleva meses activo casi siempre es un anuncio rentable, porque nadie quema presupuesto sostenidamente en algo que no convierte. En el dataset que recolecté encontré creativos en circulación desde abril de 2024, es decir más de un año pagándose sin pausa. Esos son los mensajes que vale la pena estudiar y adaptar.
Los usos prácticos para un equipo de marketing son directos:
- Benchmark de oferta: comparar precios, modalidades (100 % online vs. híbrida) y horas acreditadas frente a la competencia.
- Detección de huecos de mercado: temas con poca pauta donde hay menos competencia por la atención.
- Inspiración de copy y creativos: mapear titulares, llamados a la acción (CTA) y ganchos que ya están validados por el gasto sostenido.
- Vigilancia de campañas: detectar cuándo un competidor lanza o retira una promoción.
¿Qué tecnología usa este proyecto?
El sistema combina cinco piezas, cada una con una responsabilidad clara, de modo que puedes reemplazar cualquiera sin romper el resto. Es una arquitectura ligera, sin servidores ni APIs de pago caras: corre entera en tu PC y el único costo variable es el procesamiento de imágenes con IA, que en mi caso fue de aproximadamente 1,35 USD por 1.488 imágenes.
| Etapa | Tecnología | Para qué |
|---|---|---|
| Fuente de datos | Biblioteca de anuncios de Meta | Repositorio público y oficial de toda la publicidad activa |
| Extracción | JavaScript en la consola de Chrome | Bajar textos a CSV e imágenes sin instalar nada |
| ETL | Python + pandas + SQLite | Deduplicar, parsear fechas y clasificar temas |
| Visión por IA | Claude Haiku 4.5 (Batch API) | Leer precios y nombres de programa desde las imágenes |
| Dashboard | Streamlit + Plotly | Explorar KPIs, rankings, galería e inteligencia visual |
La elección clave es usar la consola del navegador en lugar de Selenium o Playwright. Como la Biblioteca de Meta es una página pública que ya cargaste en tu sesión, un script de consola lee el DOM tal cual lo ves, sin pelear con login, captchas ni detección de bots. Es la vía más rápida para un análisis puntual.
Nota sobre uso responsable: la Biblioteca de anuncios de Meta es un portal público creado por la propia Meta para dar transparencia a la publicidad. Aquí solo leemos datos que cualquier persona ve en pantalla y los usamos con fines de análisis de mercado. No accedemos a información privada ni a datos personales.
Paso 1: Obtener los datos desde la Biblioteca de anuncios de Meta
El primer paso es abrir la Biblioteca de anuncios de Meta en facebook.com/ads/library, filtrar por país y categoría, y escribir tu palabra clave de búsqueda. Este portal muestra todos los anuncios activos (y muchos inactivos) de cualquier anunciante, con su identificador de biblioteca, fecha de inicio, plataformas y creativos.
Para el caso de posgrados configuré la búsqueda así:
- País: Ecuador.
- Tipo de anuncio: Todos los anuncios.
- Palabra clave:
posgrado(puedes repetir conmaestría,diplomado, etc.). - Estado: Anuncios activos (para quedarte solo con campañas vivas).

Cada tarjeta trae los datos que vamos a extraer: el identificador de la biblioteca, el estado (Activo/Inactivo), la fecha «En circulación desde», las plataformas (Facebook, Instagram, Messenger, WhatsApp), el anunciante, el texto del anuncio y la imagen. Antes de extraer, haz scroll hacia abajo para que Meta cargue tantos anuncios como necesites: el script solo ve lo que ya está en pantalla.
Paso 2: Abrir la consola de Chrome
La consola de Chrome es el panel donde pegaremos y ejecutaremos los dos scripts de extracción. Es una herramienta de desarrollador incluida en cualquier navegador basado en Chromium (Chrome, Edge, Brave) que permite correr JavaScript sobre la página que estás viendo, sin instalar absolutamente nada.
Para abrirla, con la Biblioteca de anuncios cargada:
- Presiona
F12(oCtrl+Shift+I). - En la barra superior del panel, haz clic en la pestaña Console.

Si es la primera vez que pegas código en la consola, Chrome puede pedirte que escribas la palabra allow (o permitir) como medida de seguridad contra el autopegado malicioso. Escríbela una vez y ya podrás pegar libremente. Verás los mensajes de progreso (✅, ⚠️, 🎉) directamente en este panel mientras los scripts corren.
Paso 3: Extraer los textos de los anuncios a un CSV
Este script recorre todas las tarjetas visibles, extrae los campos de cada anuncio y descarga automáticamente un archivo CSV con codificación UTF-8. Para usarlo, copia el bloque completo, pégalo en la consola y presiona Enter; en segundos se descargará un archivo con nombre fb_ads_AAAA-MM-DD.csv.
El script localiza cada tarjeta a partir del texto «Identificador de la biblioteca:», sube por el DOM hasta encontrar el contenedor completo del anuncio y extrae doce campos: ID, anunciante, estado, fecha de inicio, número de plataformas, si tiene varias versiones, el texto, el titular, la URL de destino, la URL real, y el CTA.
(function () {
'use strict';
const ads = [];
/* ── PASO 1: Encontrar todos los spans con ID de biblioteca ── */
const idSpans = [...document.querySelectorAll('span, div')]
.filter(el =>
el.childElementCount === 0 &&
el.textContent.trim().startsWith('Identificador de la biblioteca:')
);
if (idSpans.length === 0) {
console.warn('⚠️ No se encontraron cards. Haz scroll para cargar más anuncios.');
return;
}
console.log(`📋 IDs encontrados: ${idSpans.length}`);
/* ── PASO 2: Para cada ID, escalar el DOM hasta encontrar la card completa ── */
idSpans.forEach((idSpan, idx) => {
let card = idSpan.parentElement;
let steps = 0;
while (card && steps < 50) {
const txt = card.innerText || '';
const count = (txt.match(/Identificador de la biblioteca:/g) || []).length;
if (count > 1) {
// subimos demasiado → retroceder un nivel
card = card.children[0] || card;
break;
}
// La card válida debe tener fechas Y algún contenido
const hasDate = txt.includes('En circulación desde');
const hasContent = txt.includes('Publicidad') ||
txt.includes('Ver detalles del anuncio') ||
card.querySelector('[data-testid="ad-library-dynamic-content-container"]');
if (hasDate && hasContent) break;
card = card.parentElement;
steps++;
}
if (!card) { console.warn(`⚠️ Card ${idx+1}: container no encontrado`); return; }
/* ── Extracción de campos ── */
const leaves = el => [...el.querySelectorAll('*')]
.filter(n => n.childElementCount === 0 && n.textContent.trim().length > 0)
.map(n => n.textContent.trim());
const find = (fn) => leaves(card).find(fn) || '';
const findAll = (fn) => leaves(card).filter(fn);
// ID de biblioteca
const libraryId = idSpan.textContent
.replace('Identificador de la biblioteca:', '').trim();
// Estado
const status = find(t => ['Activo','Inactivo','Inactiva'].includes(t));
// Fecha de circulación
const startDate = find(t => t.startsWith('En circulación desde'));
// Plataformas — contar iconos (máscaras SVG)
const platformCount = card.querySelectorAll('[style*="mask-image"]').length;
// Múltiples versiones
const multiVersion = card.innerText.includes('Este anuncio tiene varias versiones') ? 'Sí' : 'No';
// Anunciante: primer enlace a facebook.com
const advLink = [...card.querySelectorAll('a')]
.find(a => a.href && a.href.includes('facebook.com/'));
const advertiser = advLink ? advLink.textContent.trim() : '';
// Texto del anuncio (selector estable)
const adTextEl = card.querySelector('._7jyr')
|| card.querySelector('[data-testid="ad-library-dynamic-content-container"]');
let adText = '';
if (adTextEl) {
adText = adTextEl.innerText.trim().replace(/\n+/g, ' | ');
} else {
// Fallback: buscar el bloque de texto más largo que no sea metadata
const SKIP = /^(Activo|Inactivo|Publicidad|En circulación|Identificador|Plataformas|Este anuncio|Transparencia|Ver detalles)/i;
const candidates = findAll(t => t.length > 40 && !SKIP.test(t));
adText = candidates.slice(0, 3).join(' | ');
}
// URL destino visible
const urlEl = [...card.querySelectorAll('div')]
.find(d => d.childElementCount === 0 && /^HTTPS?:\/\//i.test(d.textContent.trim()));
const destUrl = urlEl ? urlEl.textContent.trim() : '';
// Titular (headline) — div con estilo line-height ~14px y contenido corto-medio
const headlineEl = [...card.querySelectorAll('div')]
.find(d => {
const s = d.getAttribute('style') || '';
const t = d.textContent.trim();
return d.childElementCount === 0 &&
s.includes('14px') && s.includes('28px') &&
t.length > 3 && t.length < 200 &&
!/^HTTPS?:\/\//i.test(t) &&
!['Apply Now','Más información','Registrarse','Saber más'].includes(t);
});
const headline = headlineEl ? headlineEl.textContent.trim() : '';
// CTA
const CTA_LIST = ['Apply Now','Learn More','Sign Up','Get Quote','Shop Now',
'Más información','Registrarse','Contactar','Ver más','Descargar',
'Saber más','Obtener oferta','Reservar','Solicitar','Inscribirse'];
const ctaEl = [...card.querySelectorAll('div')]
.find(d => d.childElementCount === 0 && CTA_LIST.includes(d.textContent.trim()));
const cta = ctaEl ? ctaEl.textContent.trim() : '';
// URL real del enlace
const extLink = [...card.querySelectorAll('a')]
.find(a => a.href && (
a.href.includes('l.facebook.com/l.php') ||
(a.href.startsWith('http') && !a.href.includes('facebook.com'))
));
const realUrl = extLink ? extLink.href : '';
ads.push({
'#': idx + 1,
'ID Biblioteca': libraryId,
'Anunciante': advertiser,
'Estado': status,
'Fecha Inicio': startDate,
'Plataformas (n)': platformCount,
'Varias Versiones': multiVersion,
'Texto Anuncio': adText,
'Titular': headline,
'URL Destino': destUrl,
'URL Real': realUrl,
'CTA': cta,
});
console.log(`✅ ${idx+1}. [${libraryId}] ${advertiser || '(sin nombre)'}`);
});
if (ads.length === 0) { console.error('❌ No se extrajeron datos.'); return; }
/* ── PASO 3: Generar CSV con BOM UTF-8 ── */
const headers = Object.keys(ads[0]);
const esc = v => `"${String(v ?? '').replace(/"/g, '""').replace(/[\r\n]+/g, ' ')}"`;
const csv = '' + [
headers.map(esc).join(','),
...ads.map(a => headers.map(h => esc(a[h])).join(','))
].join('\n');
const blob = new Blob([csv], { type: 'text/csv;charset=utf-8;' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = `fb_ads_${new Date().toISOString().slice(0,10)}.csv`;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
console.log(`\n🎉 CSV descargado → ${ads.length} anuncios | fb_ads_${new Date().toISOString().slice(0,10)}.csv`);
})();Si la consola muestra el aviso ⚠️ No se encontraron cards, significa que no hay tarjetas cargadas todavía: vuelve a la página, haz scroll y reejecuta. El CSV resultante usa BOM UTF-8, así que abre correctamente en Excel con tildes y eñes intactas.
Paso 4: Descargar las imágenes de los anuncios
Este segundo script descarga la imagen principal de cada anuncio y la guarda con un nombre que coincide con el identificador de biblioteca, de modo que después puedas cruzar cada imagen con su fila del CSV. Funciona igual: copia, pega en la consola, Enter, y se descargarán los archivos uno a uno con el nombre ad_<ID>.jpg.
La parte importante es cómo distingue la imagen del anuncio del avatar y los iconos de interfaz: descarta cualquier imagen menor a 80 px, los avatares de 60×60 y los recursos estáticos de Facebook (rsrc.php), quedándose solo con el creativo real alojado en fbcdn.net. Incluye una pausa de 500 ms entre descargas para no saturar el navegador.
(async function () {
'use strict';
/* ── Configuración ── */
const DELAY_MS = 500; // pausa entre descargas (ms)
const PREFIX = "ad_"; // prefijo del nombre de archivo
const MIN_PX = 80; // tamaño mínimo de imagen en px
const SKIP_NO_IMG = true; // omitir cards sin imagen
/* ── Localizar todas las cards por su ID de biblioteca ── */
const idSpans = [...document.querySelectorAll('span, div')]
.filter(el =>
el.childElementCount === 0 &&
el.textContent.trim().startsWith('Identificador de la biblioteca:')
);
if (!idSpans.length) {
console.warn('⚠️ No se encontraron cards. Haz scroll para cargar más anuncios.');
return;
}
console.log(`📋 Cards detectadas: ${idSpans.length}`);
console.log('🔍 Analizando imágenes...');
/* ── Para cada card: obtener Library ID + imagen principal ── */
const jobs = [];
idSpans.forEach((idSpan, idx) => {
/* Escalar DOM hasta el container de la card */
let card = idSpan.parentElement;
let steps = 0;
while (card && steps < 50) {
const txt = card.innerText || '';
const count = (txt.match(/Identificador de la biblioteca:/g) || []).length;
if (count > 1) { card = card.children[0] || card; break; }
if (txt.includes('En circulación desde') &&
(txt.includes('Publicidad') ||
txt.includes('Ver detalles del anuncio') ||
card.querySelector('[data-testid="ad-library-dynamic-content-container"]'))) {
break;
}
card = card.parentElement;
steps++;
}
if (!card) { console.warn(` ⚠️ Card ${idx+1}: container no hallado`); return; }
/* Library ID */
const libraryId = idSpan.textContent
.replace('Identificador de la biblioteca:', '').trim();
/* Buscar imagen del anuncio — excluir avatar (60×60) e iconos UI */
const allImgs = [...card.querySelectorAll('img')];
const adImg = allImgs.find(img => {
const src = img.src || img.getAttribute('src') || '';
return (
src.includes('fbcdn.net') &&
!src.includes('s60x60') &&
!src.includes('rsrc.php') &&
img.naturalWidth > MIN_PX &&
img.naturalHeight > MIN_PX
);
});
const imgSrc = adImg?.src || '';
if (!imgSrc && SKIP_NO_IMG) return; // omitir si no hay imagen
jobs.push({ libraryId, imgSrc, num: idx + 1, total: idSpans.length });
});
if (!jobs.length) {
console.warn('⚠️ No se encontraron imágenes para descargar.');
return;
}
/* ── Descargar imágenes una a una con pausa ── */
let ok = 0, skip = 0, fail = 0;
for (const job of jobs) {
await new Promise(r => setTimeout(r, DELAY_MS));
if (!job.imgSrc) {
skip++;
console.log(` ⏭️ ${job.num}/${job.total} → ${PREFIX}${job.libraryId} (sin imagen inline)`);
continue;
}
try {
const resp = await fetch(job.imgSrc);
if (!resp.ok) throw new Error(`HTTP ${resp.status}`);
const blob = await resp.blob();
const ext = blob.type.includes('png') ? 'png'
: blob.type.includes('gif') ? 'gif'
: blob.type.includes('webp') ? 'webp'
: 'jpg';
const filename = `${PREFIX}${job.libraryId}.${ext}`;
/* Leer dimensiones reales del blob */
const bmp = await createImageBitmap(blob).catch(() => null);
const dim = bmp ? `(${bmp.width}×${bmp.height})` : '';
const a = document.createElement('a');
a.href = URL.createObjectURL(blob);
a.download = filename;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(a.href);
ok++;
console.log(` ✅ ${job.num}/${job.total} → ${filename} ${dim}`);
} catch (e) {
fail++;
console.warn(` ❌ ${job.num}/${job.total} → ${PREFIX}${job.libraryId}: ${e.message}`);
}
}
console.log(
`\n🎉 Descarga completa | ✅ ${ok} imágenes | ⏭️ ${skip} sin imagen | ❌ ${fail} errores`
);
})();Como Chrome descarga decenas de archivos seguidos, la primera vez te pedirá permiso para «descargar varios archivos»: acéptalo. Al terminar tendrás una carpeta de imágenes lista para el análisis visual, y cada archivo se llamará igual que su ID Biblioteca en el CSV, lo que permite unir ambas fuentes sin ambigüedad.
Paso 5: Procesar los datos con el pipeline ETL en Python
El pipeline ETL toma todos los archivos fb_ads_*.csv que descargaste, los carga en una base de datos SQLite, elimina duplicados y clasifica cada anuncio por tema. Es incremental: solo procesa archivos nuevos o modificados, así que puedes acumular extracciones de distintas fechas sin reprocesar todo.
La clasificación temática es un diccionario de palabras clave ordenado por especificidad: categoriza cada anuncio en temas como Seguridad Ocupacional, Recursos Humanos, Logística y Supply Chain, Sostenibilidad o Gestión Pública según el texto del creativo. Para ejecutarlo:
python pipeline.pyEl parseo de fechas merece una mención: Meta muestra las fechas en español abreviado («4 may 2026»), así que el pipeline incluye un mapa de meses (ene, feb, mar…) para convertir el texto «En circulación desde el 23 abr 2024» en una fecha real con la que calcular la longevidad de cada anuncio. Esa fecha es la base del análisis de «Más Longevos» en el dashboard.
Paso 6: Extraer precios desde las imágenes con IA
Muchos anuncios de posgrados ponen el precio dentro de la imagen, no en el texto, así que para capturarlo uso un modelo de visión: Claude Haiku 4.5 mediante la Batch API, que aplica un 50 % de descuento sobre el procesamiento normal. El script analiza cada imagen descargada y extrae únicamente datos visibles y explícitos: precio, nombre del programa y modalidad.
El costo es muy bajo gracias a la Batch API: procesar 1.488 imágenes me costó alrededor de 1,35 USD. Necesitas un archivo .env con tu ANTHROPIC_API_KEY y luego ejecutar:
python extract_images.pyLos resultados se guardan en data/image_extractions.json y en una tabla de la base de datos, lista para que el dashboard cruce cada precio con su anunciante. Este paso es opcional: si solo te interesa el texto y la longevidad, puedes saltarlo. Pero para un benchmark de precios es justo lo que convierte una pila de imágenes en una tabla comparable.
Paso 7: Explorar el dashboard de inteligencia de anuncios
El dashboard es una app de Streamlit con seis secciones que convierten la base de datos en respuestas accionables de marketing. Se levanta con un solo comando y se abre automáticamente en el navegador en http://localhost:8501:
streamlit run app.pyLas secciones están pensadas para responder una pregunta cada una:
- 📊 Resumen Ejecutivo — KPIs globales: total de anuncios, anunciantes únicos, % activos y antigüedad media de las campañas.
- 🏢 Por Anunciante — ranking de quién invierte más en pauta, con drilldown a cada institución.
- 🏷️ Por Tema — qué categorías de posgrado están saturadas y cuáles tienen hueco.
- ⏱️ Más Longevos — los anuncios con más tiempo en circulación, la mejor pista de qué mensajes convierten.
- 🖼️ Galería — los creativos reales, para inspirar copy y diseño.
- 🤖 Inteligencia Visual — los precios extraídos con IA, para el benchmark de oferta.
Con esto el ciclo queda cerrado: del portal público de Meta a un tablero interactivo que cualquier persona de marketing puede explorar sin escribir una línea de código. Cuando quieras actualizar los datos, repites los pasos 1 a 4, vuelves a correr el pipeline y el dashboard refleja la nueva extracción.
¿Qué revelan los datos? Interpretación de resultados
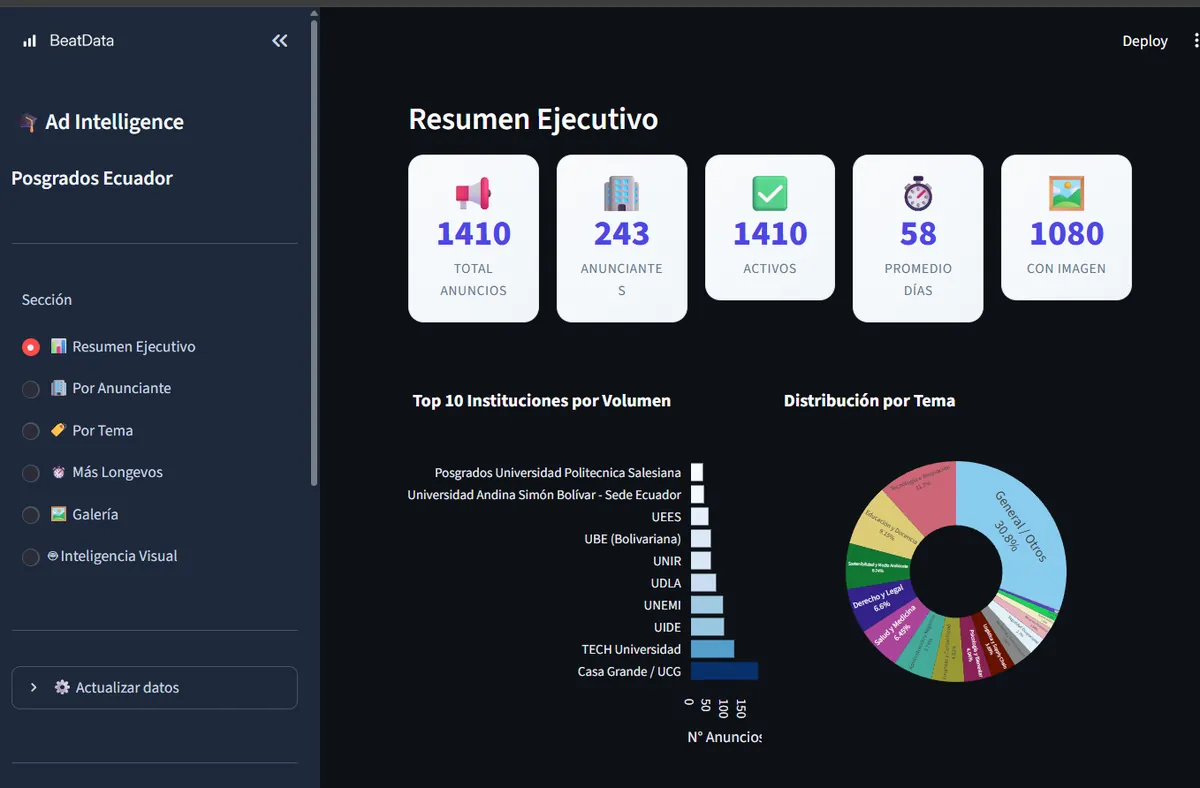
El análisis de 1.410 anuncios activos de posgrados en Ecuador, de 243 anunciantes distintos, muestra un mercado concentrado en pocas instituciones, dominado por mensajes genéricos y con una rotación de creativos alta sobre un núcleo pequeño de campañas muy longevas. Estas son las cinco lecturas que saqué del Resumen Ejecutivo del dashboard (portada de este artículo).
El mercado está concentrado en pocos jugadores
Aunque hay 243 anunciantes, la pauta se concentra en la cabeza de la tabla. Los tres primeros —Casa Grande / UCG con 221 anuncios, TECH Universidad con 124 y UNEMI con 97— suman alrededor del 30 % de todo el volumen. Casa Grande / UCG sola representa cerca del 15 % del mercado de anuncios.
Detrás vienen UIDE (95), UDLA (72), UNIR (59), UBE Bolivariana (58) y UEES (50). La lectura de marketing es clara: competir por impresiones contra Casa Grande o TECH en su propio terreno es caro, porque saturan el feed. Para un actor mediano conviene buscar diferenciación por tema o por mensaje antes que por volumen bruto.
Casi un tercio de los anuncios no comunica una especialidad clara
La categoría más grande es General / Otros con el 30,8 %, lo que significa que casi un tercio de los creativos no segmenta el mensaje por área de conocimiento. Le siguen Tecnología e Innovación (11,7 %) y Educación y Docencia (9,5 %) como las verticales más pauteadas —y por tanto más saturadas—.
En el otro extremo, temas como Marketing y Comunicación (3,1 %), Seguridad Ocupacional (3,1 %) o Logística y Supply Chain (3,6 %) reciben muy poca pauta. Ese contraste es donde aparece la oportunidad: nichos con demanda real pero poca competencia por la atención, en los que un mensaje específico destaca más que en las áreas saturadas.
La mayoría de los creativos rota rápido, pero hay un núcleo que no se apaga
La duración de las campañas es muy desigual. La mitad de los anuncios lleva menos de un mes en circulación (mediana cercana a 29 días), señal de mucha prueba y descarte. Pero el promedio sube a 58 días porque un grupo reducido lleva muchísimo más tiempo activo.
Ese núcleo es el más valioso: 29 anuncios superan los 180 días en circulación y unos pocos pasan el año, con el más longevo acumulando alrededor de 596 días sin pausa. Cuando un anunciante mantiene un creativo activo más de seis meses, casi siempre es porque convierte. Esos son los anuncios que conviene diseccionar —titular, oferta, imagen y CTA— antes de diseñar los propios.
Los precios viven en las imágenes, no en el texto
Aquí es donde la visión por IA aportó lo que el texto no tenía. De las imágenes analizadas con Claude extraje precios en 158 anuncios con cuota mensual (mediana cercana a 140 USD) y 45 con precio total visible (mediana de unos 2.200 USD, en un rango amplísimo de 200 a 20.000 USD según el tipo de programa). Además, el modelo identificó el nombre del programa en 1.130 imágenes.
La conclusión práctica: poner el precio dentro del creativo es una práctica extendida en este mercado, y el ticket varía tanto que conviene posicionarse a sabiendas de dónde cae tu oferta dentro de ese rango, no a ciegas.
El formato visual domina
Con 1.080 de 1.410 anuncios usando imagen (cerca del 77 %), el creativo estático es el formato dominante de este mercado. Quien quiera competir necesita una imagen sólida con el mensaje y, en muchos casos, el precio incrustados —no basta con el texto del anuncio—.
Errores comunes y cómo resolverlos
La mayoría de los problemas vienen de la fase de extracción en la consola, no del análisis en Python. La tabla siguiente resume los fallos típicos, su causa y la solución concreta para cada uno.
| Síntoma | Causa | Solución |
|---|---|---|
⚠️ No se encontraron cards |
No hay anuncios cargados en el DOM | Haz scroll hacia abajo y reejecuta el script |
| El CSV abre con caracteres raros en Excel | Excel ignoró el BOM | Ábrelo con Datos → Desde texto y elige UTF-8 |
| Chrome bloquea las descargas múltiples | Permiso no concedido | Acepta «descargar varios archivos» en el aviso |
| Faltan imágenes de algunos anuncios | El creativo es un video o carrusel | Es esperado: el script omite cards sin imagen estática |
| El pipeline no carga un CSV nuevo | El archivo no coincide con el patrón | Renómbralo a fb_ads_AAAA-MM-DD.csv |
ANTHROPIC_API_KEY no encontrada |
Falta el archivo .env |
Crea .env con tu clave antes de correr extract_images.py |
Preguntas frecuentes
¿Es legal extraer datos de la Biblioteca de anuncios de Meta? La Biblioteca de anuncios es un portal público que la propia Meta creó para dar transparencia a la publicidad. Aquí solo se leen datos visibles para cualquier usuario y se usan con fines de análisis de mercado. Aun así, revisa siempre los términos de uso vigentes de Meta y evita un volumen de peticiones que parezca abuso.
¿Necesito saber programar para usar esto? Para la extracción no: basta copiar y pegar dos scripts en la consola del navegador. Para el procesamiento y el dashboard necesitas Python instalado y ejecutar tres comandos. No hay que escribir código nuevo.
¿Funciona para otros sectores además de posgrados? Sí. Solo cambias la palabra clave de búsqueda y, si quieres, las categorías de clasificación temática del pipeline. La misma arquitectura sirve para inmobiliarias, gimnasios, retail o cualquier mercado que pautee en Meta.
¿Por qué la longevidad de un anuncio es tan importante? Porque la pauta cuesta dinero todos los días. Si un competidor mantiene un anuncio activo durante meses, lo más probable es que ese anuncio sea rentable. La longevidad es una señal de mercado gratuita sobre qué mensajes y ofertas funcionan.
Conclusión
La inteligencia de anuncios deja de ser un lujo de grandes agencias cuando la fuente es pública y las herramientas son gratuitas. Con dos scripts de consola, un pipeline de Python y un dashboard de Streamlit construí un sistema que responde, con datos reales, qué hace la competencia en el mercado de posgrados de Ecuador: quién invierte, qué cobra y qué mensajes lleva más de un año pagando.
El mismo flujo es reutilizable para cualquier sector: cambia la palabra clave, repite la extracción y deja que el análisis te muestre dónde está el hueco de mercado. La parte difícil del marketing competitivo nunca fue conseguir los datos —están a la vista en la Biblioteca de Meta— sino estructurarlos para decidir con ellos. Eso es exactamente lo que automatiza este proyecto.
Deja una respuesta